Why this matters: Mastering these control systems transforms you from a casual user to a precision engineer, enabling you to extract reliable, structured, and nuanced outputs from any language model.
🎯 Try This First
Before we dive into theory, experience the power of prompt engineering. Type a simple task below, then watch how structure changes everything:

Basic Prompt vs. Engineered Prompt
The Anatomy of a Control-Optimized Prompt
Every effective prompt follows a hierarchical structure. Think of it as programming an intelligent system rather than having a casual conversation.

Why Structure Matters
LLMs process tokens sequentially. Information placement affects attention weights. Early context primes the model's "mindset," while constraints at the end act as guardrails.
System vs. User Roles: The Control Hierarchy
Modern LLM APIs distinguish between system messages (persistent context) and user messages (per-turn instructions). This separation is your primary control lever.
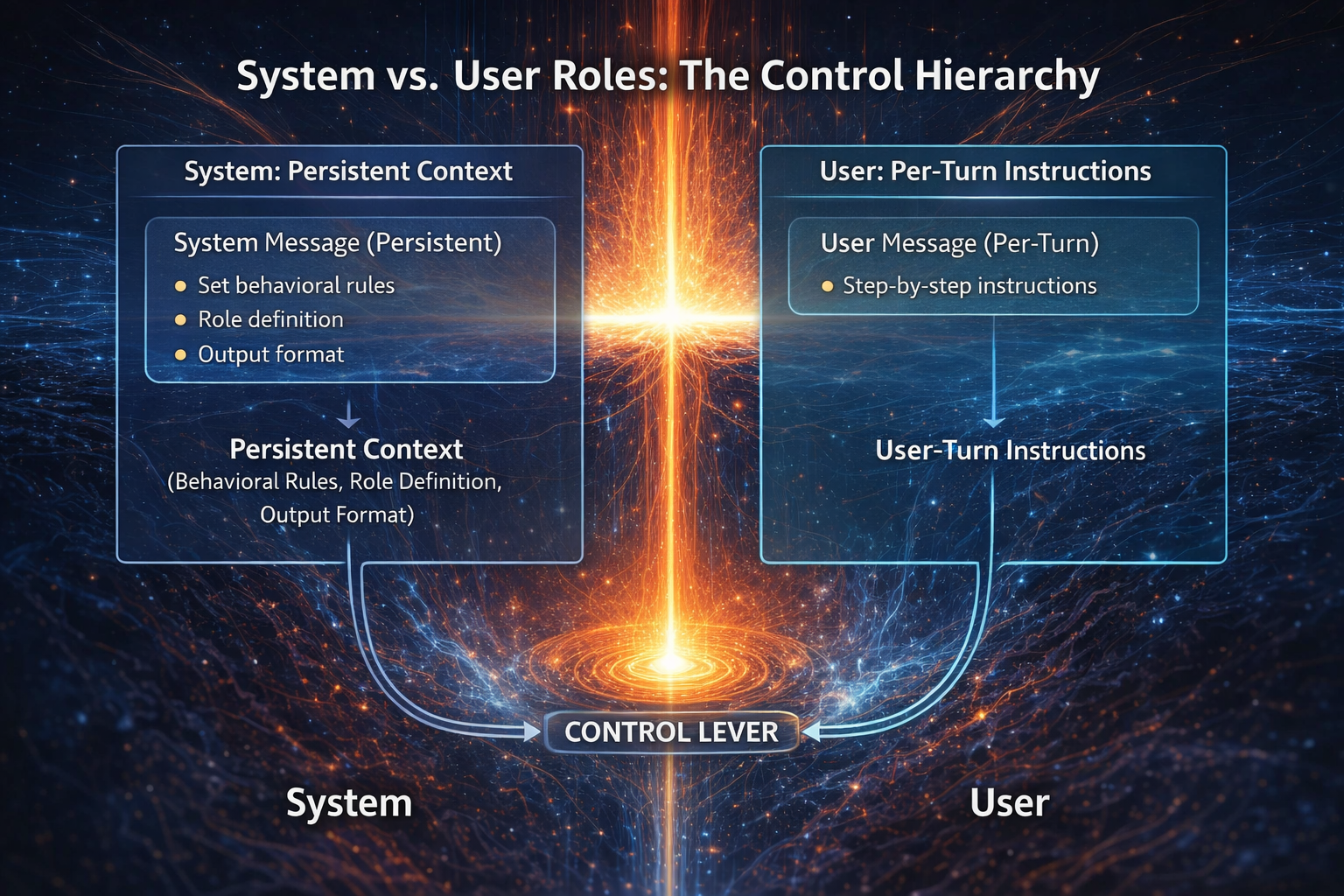
Purpose: Set behavioral rules, role definition, output format.
Example: "You are a Python code reviewer. Always output in JSON format with keys: issue, severity, fix."
Purpose: Provide specific task, input data.
Example: "Review this code: [code snippet]"
Key Principle
System messages have stronger "weight" in the model's attention. Use them for rules you want enforced consistently across multiple turns.
Instruction Design Patterns
The verb and structure of your instruction dramatically affects output quality. Use imperative, specific action verbs.
"Tell me about climate change impacts."
Too vague, no constraints, ambiguous scope.
"Analyze three primary economic impacts of climate change on coastal cities. For each impact, provide: (1) mechanism, (2) quantitative example, (3) mitigation strategy. Use bullet points."
Specific verb, constrained scope, defined structure.
Action Verb Hierarchy
- Analyze: Break down into components
- Compare: Identify similarities/differences
- Synthesize: Combine multiple sources
- Evaluate: Assess quality/effectiveness
- Generate: Create new content
Few-Shot Learning: Teaching by Example
Instead of describing what you want, show the model examples. This is the most powerful control technique for complex outputs.

Best Practices
- Provide 2-5 examples (more isn't always better)
- Show edge cases if they matter
- Keep examples structurally consistent
- Place examples before the actual task
Knowledge Check 1
In the 5-Layer Prompt Architecture, which layer should contain rules about what the model should NOT do?
Chain-of-Thought (CoT): Making Models "Think"
By instructing the model to show its reasoning steps, you dramatically improve accuracy on complex tasks—especially math, logic, and multi-step problems.

Prompt: "If a train travels 60 mph for 2.5 hours, then 80 mph for 1.5 hours, how far did it travel?"
Model: "210 miles" ❌ (incorrect)
Prompt: "Solve this step-by-step, showing your work: If a train travels 60 mph for 2.5 hours, then 80 mph for 1.5 hours, how far did it travel?"
Model:
Step 1: 60 × 2.5 = 150 miles
Step 2: 80 × 1.5 = 120 miles
Step 3: 150 + 120 = 270 miles ✓
CoT Activation Phrases
- "Let's think step by step"
- "Show your reasoning before answering"
- "Break this down into steps"
- "Explain your thought process"
Output Format Control: Structured Data Extraction
For applications that consume LLM outputs programmatically, you need reliable, parseable formats. Explicit format instructions are essential.

Format Enforcement Techniques
- Explicit schema: Define exact keys/structure
- Example output: Show a sample formatted response
- Validation rules: "Output must be valid JSON"
- Constrained generation: Some APIs support schema enforcement
Knowledge Check 2
What is the primary benefit of using Chain-of-Thought (CoT) prompting?
Temperature & Sampling: Controlling Randomness
Beyond prompt engineering, API parameters like temperature, top_p, and top_k control output randomness and creativity.
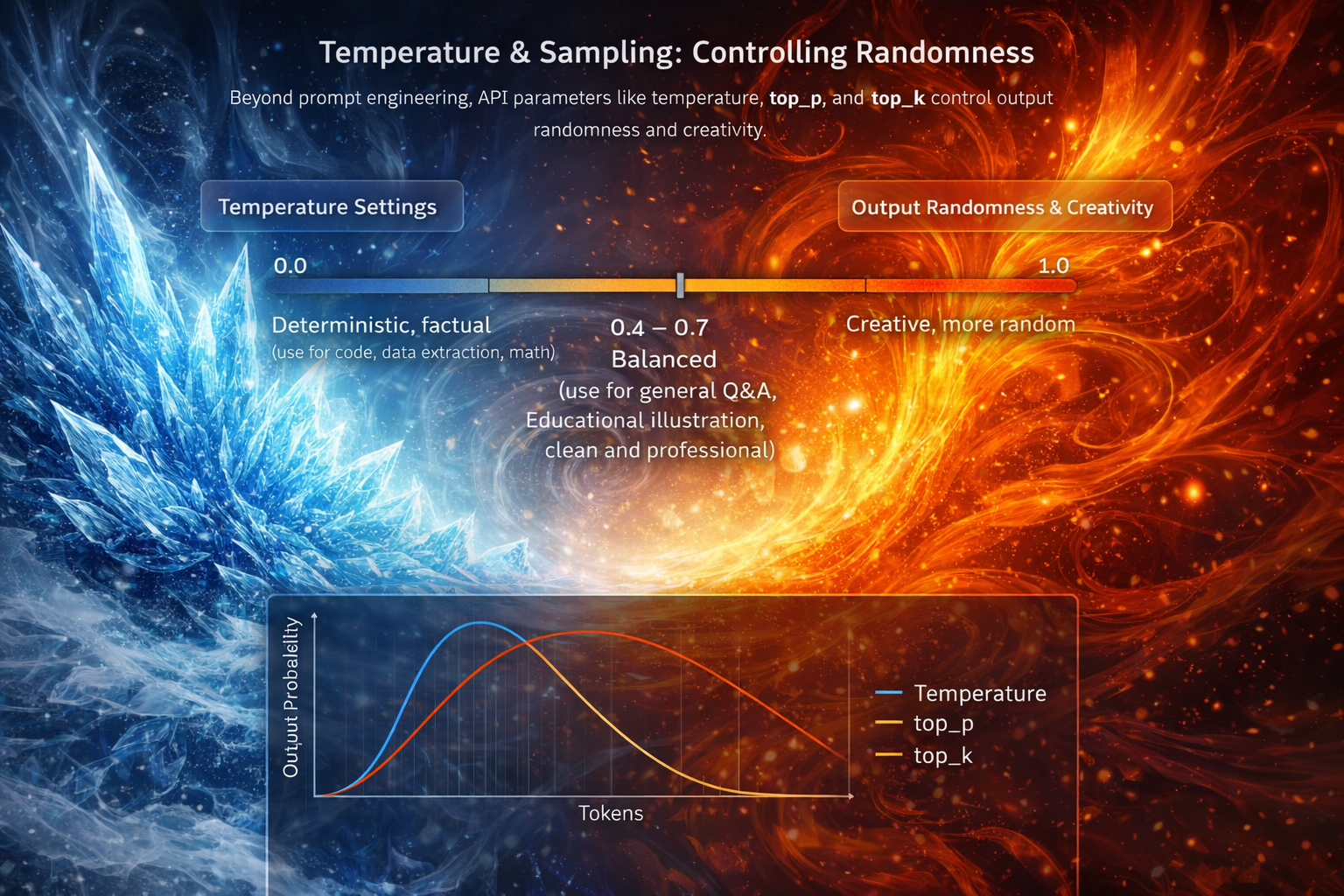
Temperature Settings
- 0.0 - 0.3: Deterministic, factual (use for code, data extraction, math)
- 0.4 - 0.7: Balanced (use for general Q&A, summaries)
- 0.8 - 1.0: Creative, diverse (use for brainstorming, creative writing)
- 1.0+: Highly random, often incoherent
- Code generation: temp = 0.1
- Technical documentation: temp = 0.3
- Customer support: temp = 0.5
- Marketing copy: temp = 0.8
- Poetry: temp = 1.0
Top-p (Nucleus Sampling)
Alternative to temperature. Top-p=0.9 means "consider only the tokens that make up the top 90% probability mass." Lower values = more focused.
Negative Prompting: What NOT to Do
Sometimes it's easier to define boundaries than describe exactly what you want. Negative prompts tell the model what to avoid.
When to Use Negative Prompts
- Preventing common model mistakes (hallucination, overconfidence)
- Enforcing brand voice (no slang, no humor)
- Legal/compliance requirements (no medical advice, no financial predictions)
- Output length control ("do not exceed 50 words")
"Write about this medication."
Risk: Model may give medical advice.
"Describe this medication's approved uses. Do not provide dosage advice. Do not diagnose conditions. Include disclaimer."
Safe, compliant output.
Knowledge Check 3
You're building a code generation tool that must produce deterministic, factually correct outputs. What temperature setting should you use?
Retrieval-Augmented Generation (RAG)
RAG combines LLMs with external knowledge retrieval systems. Instead of relying on the model's training data, you inject relevant documents into the prompt dynamically.

How RAG Works
- Query: User asks a question
- Retrieve: System searches knowledge base for relevant docs
- Inject: Retrieved docs are inserted into the prompt as context
- Generate: Model answers based on provided context
RAG Benefits
- Up-to-date information: Not limited by training data cutoff
- Attribution: Answers cite specific sources
- Reduced hallucination: Model works from facts, not guesses
- Domain specialization: Custom knowledge without fine-tuning
Meta-Prompting: Models Critiquing Themselves
Advanced technique: Ask the model to generate, then critique and improve its own output. This multi-pass approach increases quality.

Meta-Prompting Patterns
- Generate → Critique → Revise: Quality improvement
- Generate → Evaluate → Select: Create multiple options, pick best
- Decompose → Solve → Synthesize: Break complex tasks into subtasks
- Simulate → Validate → Adjust: Test hypothetical scenarios
Note: Meta-prompting uses more tokens but significantly improves output quality for critical tasks.
Integration Best Practices
When deploying LLM control systems in production, follow these engineering principles to ensure reliability and maintainability.
Version Your Prompts
- Treat prompts like code: use version control (Git)
- Tag production-ready prompts with semantic versioning
- Document changes and performance impacts
- Enable A/B testing between prompt versions
Monitor & Iterate
- Log all prompts and responses for analysis
- Track success metrics: accuracy, latency, cost
- Collect user feedback on output quality
- Run regular evaluations on holdout test sets
- ✓ Prompt templates validated with edge cases
- ✓ Fallback strategies for API failures
- ✓ Rate limiting and retry logic implemented
- ✓ Output validation and sanitization
- ✓ Cost monitoring and budget alerts
- ✓ Compliance review for sensitive domains
⚠️ Important: Never hardcode API keys. Use environment variables and secret management systems.
🎯 Summary: Control Systems Mastery
You've learned the advanced techniques that separate expert prompt engineers from casual users. Let's recap the key principles:
- Use the 5-Layer Architecture: Context → Instruction → Input → Format → Constraint
- Leverage System vs. User roles: System = rules, User = tasks
- Show, don't tell: Few-shot learning beats long descriptions
- Activate reasoning: Chain-of-Thought for complex tasks
- Control randomness: Match temperature to use case
- Set boundaries: Negative prompts prevent unwanted outputs
- Inject knowledge: RAG for up-to-date, factual responses
- Iterate intelligently: Meta-prompting for critical quality
The quality of your output is bounded by the clarity of your input. Treat prompts as code: precise, testable, and iterative.
Ready to put your knowledge to the test? The assessment awaits!
🎓 Ready for Assessment?
You'll now answer 5 questions testing your understanding of advanced prompt engineering and control systems. You need 80% to pass.
Good luck!
Assessment Question 1 of 5
You're designing a customer support chatbot that must NEVER provide refunds or make promises about product availability. Which control technique is most appropriate?
Assessment Question 2 of 5
A legal AI assistant must extract contract terms and output them in a strict JSON schema for database insertion. Which layers of the 5-Layer Architecture are MOST critical?
Assessment Question 3 of 5
Your RAG system retrieves 5 documents, but 3 of them are outdated. What's the best prompt instruction to handle this?
Assessment Question 4 of 5
Which meta-prompting pattern is best for generating high-quality marketing copy when you need a single final output?
Assessment Question 5 of 5
You're deploying a prompt-based classifier in production. According to integration best practices, which of these is MOST critical?